
cmod.ify
DATABASE 기초 + MariaDB + DML 본문
728x90
반응형
1. 데이터베이스(DB) 기초 및 DBMS
DB 사용 목적
- 데이터와 응용 프로그램 간 종속성 최소화 (하나가 바뀌어도 다른 쪽에 영향 덜 주게 함)
- 데이터 중복 및 비일관성 최소화 (최근엔 성능 위해 일부러 중복시키기도 함)
- 구조: 응용 프로그램 ↔ DBMS ↔ 데이터베이스
DBMS (관리 시스템) 특징
- 생산성, 기능성, 신뢰성 향상 및 확장성, 부하분산(Load Balancing) 지원
- SQL 종류
- DDL: 정의 (Create, Drop 등)
- DML: 조작 (CRUD - Create, Read, Update, Delete)
- 조회는 여러 명 해도 괜찮지만, 삽입/삭제/갱신은 주의 필요
- CQRS 패턴: 읽기(NoSQL)와 쓰기(RDBMS)를 분리하여 성능 최적화 (카프카 등 메시지 브로커 활용)
- DCL: 제어 (권한 부여 등)
- TCL: 트랜잭션 제어 (Commit, Rollback)
주요 DB 종류
- MariaDB: 오픈소스. AWS 등 클라우드 이용 시 라이선스 비용 유리함
- MySQL/Oracle: 유료 라이선스 정책 주의 필요
- PostgreSQL: 복잡한 질의(Query) 처리에 강점
- Column 기반: 빅데이터 분석 및 열 단위 집계에 유리
RDBMS 키(Key) 개념
- 슈퍼키: 속성 상관없이 식별만 되면 됨.
- 후보키: 식별을 위한 최소한의 속성 조합.
- 기본키(PK): 후보키 중 선정된 메인 키 (중복X, NULL X).
- 대체키: 기본키 안 된 나머지 후보키들.
- 외래키(FK): 다른 테이블의 PK를 참조하는 키 (데이터 일관성 유지).
📐 데이터 모델링 & 관계
- 관계 설정:
- 1:1 -> 한쪽에 FK 추가.
- 1:N -> N쪽에 FK 추가 (가장 흔함).
- N:M -> 연결 테이블(매핑 테이블) 새로 만들어야 함.
- 정규화(Normalization): 중복 제거해서 이상현상(삽입/삭제/갱신 오류) 방지.
- 역정규화: 성능 향상을 위해 쪼갠 테이블을 다시 합치는 과정.
2. MariaDB 시작하기
기본 개념
- SQL 기반 관계형 DBMS (RDBMS)
- 작업 단위: 데이터베이스 > 테이블 (참고: Oracle은 User > DB > Table)
- 호출 방식: 데이터베이스명.테이블명 (현재 DB인 경우 생략 가능)
설치 및 접속
DBServer : MariaDB
설치 : https://mariadb.org/
MariaDB Foundation - MariaDB.org
… Continue reading "MariaDB Foundation"
mariadb.org
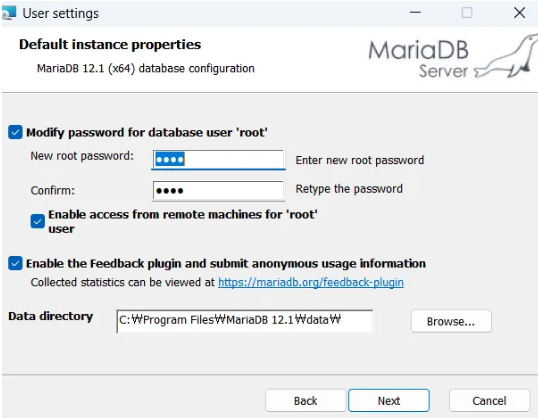
- 포트: 기본 3306 (보안상 변경 권장)
- root 계정: 보안을 위해 원격 접속은 차단하고 로컬 접속만 허용하는 것이 원칙
- 버퍼 사이즈: 메모리 점유량 결정. 학습용은 작게, 실무에선 크게 설정
- DBeaver 연결: 파일 > 새로 작성 > 데이터베이스 연결 > 정보 입력

접속 도구 : DBeaver
설치 : https://dbeaver.io/download/
Download | DBeaver Community
Download DBeaver Community 25.3.1 Released on December 21st 2025 (Milestones). It is free and open source (license). Also you can get it from the GitHub mirror. System requirements. DBeaver PRO 25.3 Released on December 8th, 2025 PRO version website: dbeav
dbeaver.io
초기세팅
파일 > 새로작성 > DBeaver > 데이터베이스 연결


접속 정보 고치고 싶으면
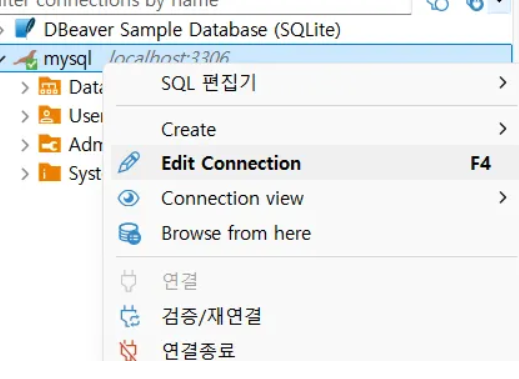
작업 시작
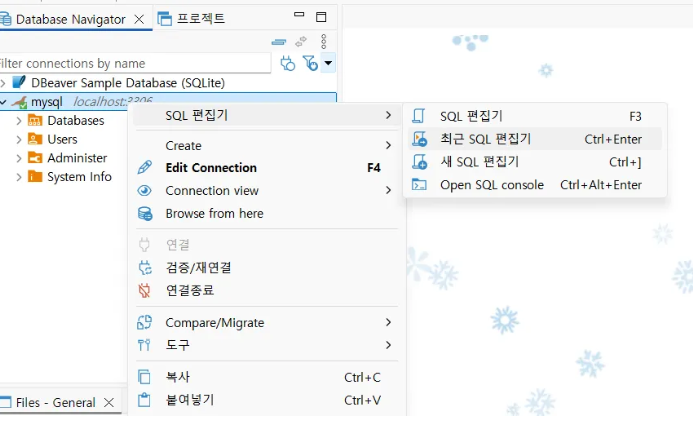
기본 명령어
- show databases;: DB 목록 확인
- select database();: 현재 사용 중인 DB 확인
- use 이름;: DB 변경
- create database 이름;: DB 생성
- show tables;: 테이블 목록 확인
3. SELECT 문 정리
기본 구조 및 실행 순서
[작성 순서] SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT
[실행 순서] FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
- 주의: SELECT에서 만든 별명은 WHERE절에서 사용 불가
주요 옵션
- AS (별명): 컬럼명 변경 출력. 공백이나 특수문자 있으면 " "로 감싸야 함
- CONCAT: 컬럼 데이터 이어붙이기 (예: 이름 + 직무)
- DISTINCT: 중복 제거. SELECT 바로 뒤에 작성
- ORDER BY: 정렬. ASC(오름차순, 기본), DESC(내림차순)
- 컬럼 순서(인덱스)로도 정렬 가능하나 가독성 위해 컬럼명 권장
SELECT [DINTINCT] * 또는 {컬럼이름 [별명]}
FROM 테이블이름 [새로운이름] 또는 SELECT 구문
[WHERE CONDITION]
[GROUP BY 그루핑할 컬럼 이름이나 연산식]
[HAVING GROUPING 후 CONDITION]
[ORDER BY {정렬한 컬럼 이름 또는 연산식 [ASC | DESC]}]
[LIMIT 행 개수 [OFFSET offset]]4. 데이터 필터링 (WHERE)
연산자 종류
- 비교: =, !=, <>, >, <
- 논리: AND, OR, NOT (우선순위: NOT > AND > OR)
- BETWEEN A AND B: A와 B 사이 값 (경계값 포함, A < B)
- IN (목록): 목록 중 하나라도 일치하면 조회
패턴 매칭 (LIKE)
- %: 글자 수 상관없음 (예: '천%'는 천으로 시작하는 모든 단어)
- _: 딱 한 글자 의미
- ESCAPE: 와일드카드 문자 자체를 검색할 때 사용 (예: LIKE '30#%' ESCAPE '#'는 '30%' 검색)
대소문자 구분
- 대소문자: 기본적으로 구분 안 함. 구분하려면 BINARY 키워드 사용하거나 콜레이션(Collation) 설정을 _bin으로 변경
SELECT *
FROM tCity
WHERE BINARY metro = 'y';
테이블 생성 시 컬럼의 콜레이션 설정
CREATE TABLE NAME(
컬럼이름 자료형 COLLATE utf8mb4__bin,
);
기존 테이블 변경
ALTER TABLE 테이블이름 MODIFY 컬럼이름 자료형 COLLATE utf8mb4_bin;NULL
- NULL: 미지의 값. 비교 연산자(=) 사용 불가. 반드시 IS NULL 또는 IS NOT NULL 사용
5. 집계 및 그룹화 (GROUPING)
집계 함수
- SUM, AVG, MAX, MIN, COUNT 등
- 특징: NULL 값은 연산에서 제외됨
- COUNT(*): 전체 행 개수 (NULL 포함)
- COUNT(컬럼): 해당 컬럼이 NULL이 아닌 행 개수
집계함수 NULL 처리 주의사항
- 집계 함수(AVG, SUM, COUNT 등)는 기본적으로 NULL 데이터를 연산 대상에서 제외함
- 산술 연산(+, -, *, /)에 NULL이 포함되면 결과는 무조건 NULL이 됨
1. 데이터에 NULL이 없는 경우 (Salary 컬럼)
- AVG(salary): 모든 값을 더해 전체 행 개수로 나눔
- SUM(salary) / COUNT(*): 위와 동일한 결과 발생
- 결론: 두 쿼리의 결과값이 일치함
2. 데이터에 NULL이 포함된 경우 (Score 컬럼)
- AVG(score): NULL인 행을 아예 없는 셈 치고 나머지 데이터의 평균을 냄 (분모가 줄어듦)
- SUM(score) / COUNT(*): 합계는 NULL을 제외하고 구하지만, 나눌 때는 NULL을 포함한 전체 행 개수로 나눔
- 결론: 두 결과값이 서로 다름 (AVG 결과가 더 크게 나옴)
정확한 계산을 위한 팁
- NULL을 0으로 간주하고 평균을 내야 한다면 IFNULL을 사용해야 함
SQL
-- NULL을 0으로 치환하여 전체 데이터 대비 평균 계산
SELECT AVG(IFNULL(score, 0)) FROM tStaff;- IFNULL(컬럼, 대체값): NULL을 0 등으로 치환하여 평균 계산 시 왜곡 방지
결과 제한 (LIMIT)
- LIMIT 4: 상위 4개만 출력
- LIMIT 2, 3: 3번째부터 3개 출력 (0부터 시작하므로 인덱스 주의)
자료형의 특성과 성능 (CHAR vs VARCHAR)
CHAR (고정 길이 문자형)
- 특징: 설정한 크기만큼 공간을 무조건 차지함
- 용도: 데이터의 길이가 일정하거나 변경이 잦은 경우 (예: 비밀번호, 주민번호, 상태 코드)
- 장점: 데이터 수정 시 공간이 고정되어 있어 관리 효율이 높고 속도가 안정적임
VARCHAR (가변 길이 문자형)
- 특징: 실제 입력한 데이터 크기만큼만 공간을 사용함 (남는 공간은 반환)
- 용도: 데이터의 길이다 다양하거나 변경이 거의 없는 경우 (예: 아이디, 게시글 제목)
- 단점: 수정 시 데이터가 커지면 성능 저하 발생 가능
행 마이그레이션 (Row Migration) 원리
- 가변 길이(VARCHAR) 방식에서 4글자 데이터를 저장했다가 5글자로 수정하는 경우 발생
- 기존 공간이 부족하여 해당 데이터를 다른 빈 공간으로 옮겨야 함
- 결과: DB가 데이터를 찾을 때 한 번 더 이동해야 하므로 조회 성능이 떨어짐
SQL GROUPING & 집계 (GROUP BY / HAVING)
- GROUP BY: 특정 컬럼으로 데이터를 그룹화함.
- SELECT 절에는 GROUP BY에 쓴 컬럼이나 집계함수(SUM, AVG, COUNT 등)만 올 수 있음. (Oracle은 엄격, MySQL은 첫 데이터 보여줌)
- DISTINCT와 유사하게 중복 제거용으로도 활용 가능함.
- HAVING: 그룹화된 결과에 조건을 걸 때 사용함.
- WHERE는 그룹화 전 필터링, HAVING은 그룹화 후 필터링임.
- 집계함수는 WHERE절에 못 쓰고 반드시 HAVING에 써야 함.
- 팁: 미리 거를 수 있는 건 WHERE에서 거르는 게 성능상 이득임.
Window 함수 (순위 및 분석)
- 순위 함수: OVER(ORDER BY ...)와 함께 사용함.
- ROW_NUMBER(): 무조건 1, 2, 3... (일련번호)
- RANK(): 공동 순위 있으면 다음 순위 건너뜀 (1, 2, 2, 4)
- DENSE_RANK(): 공동 순위 있어도 다음 순위 안 건너뜀 (1, 2, 2, 3)
- NTILE(N): 전체를 N개 그룹으로 등분함.
- 분석 함수: LAG(이전 행), LEAD(다음 행), CUME_DIST(누적 합) 등 행 간 관계 분석에 사용함.
- PARTITION BY: 그룹별로 순위를 따로 매길 때 사용함 (예: 지역별 나이 순위).
기타 집계 및 피봇
- WITH ROLLUP: 그룹별 소계와 마지막에 전체 총계를 자동으로 만들어 줌.
- PIVOT 기능: SUM(IF(...)) 형식을 사용해 행 데이터를 열 데이터로 전환함.
728x90
반응형
'BASIC > DATABASE' 카테고리의 다른 글
| DML & TCL (0) | 2025.12.29 |
|---|---|
| DB SET Operator & Sub Query & Join (0) | 2025.12.29 |
| MariaDB DDL 실습 (0) | 2025.12.26 |
| MariaDB DDL (1) | 2025.12.26 |
| MariaDB 기초 실습 문제 (0) | 2025.12.24 |